Floating Reference Hypothesis
One way to alleviate potential numerical
issues in evaluating
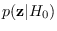 and/or
and/or
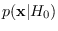 ,
is with a floating reference hypothesis.
Under certain conditions, the reference hypothesis
,
is with a floating reference hypothesis.
Under certain conditions, the reference hypothesis 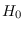 may be changed “on the fly" to alleviate
numerical or PDF approximation issues with the
calculation of the J-function.
Loosely stated, is allowed to vary within a set
of hypotheses that can be optimally distinguished
using the feature
may be changed “on the fly" to alleviate
numerical or PDF approximation issues with the
calculation of the J-function.
Loosely stated, is allowed to vary within a set
of hypotheses that can be optimally distinguished
using the feature 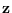 . For example, as long as
contains the sample variance, which is a sufficient
statistic for distinguishing two zero-mean Gaussian densities
that differ only in variance, then may be
the zero-mean Gaussian distribution with
arbitrary variance - as the assumed variance
varies, the numerator and denominator
terms of the J-function vary over a wide range, but the
ratio (the J-function) remains constant.
Therefore, for numerical convenience, we can set the variance
to the value at or near the maximum of both the numerator and denominator.
. For example, as long as
contains the sample variance, which is a sufficient
statistic for distinguishing two zero-mean Gaussian densities
that differ only in variance, then may be
the zero-mean Gaussian distribution with
arbitrary variance - as the assumed variance
varies, the numerator and denominator
terms of the J-function vary over a wide range, but the
ratio (the J-function) remains constant.
Therefore, for numerical convenience, we can set the variance
to the value at or near the maximum of both the numerator and denominator.
We first define the region of sufficiency (ROS)
of feature set transformation
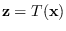 , denoted by
, denoted by
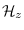 , as a set of hypotheses such that
every pair of hypotheses
, as a set of hypotheses such that
every pair of hypotheses
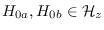 obeys the relationship
obeys the relationship
Thus, a likelihood ratio between any two hypotheses in
can be optimally constructed either in the raw data or in the feature space without loss of information.
An ROS may be thought of as a family of PDFs traced out by the parameters
of a PDF where is a sufficient statistic for the
parameters.
We can re-arrange the above equation as follows:
Thus, the “J-function",
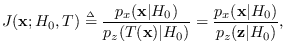 |
(2.13) |
is independent of as long as remains within
ROS
.
Defining the ROS should in no way be interpreted as a sufficiency requirement
for . Every feature has a ROS, because
at the very least, the projected PDF itself (2.2)
serves a one hypothesis, and as another,
for which the feature is sufficient.
As long as the feature contains an energy statistic
(see Section 3.2.2),
the J-function is independent of scale parameters in .
Example 3
We re-visit example 1 with an eye to using
a floating reference hypothesis.
Let
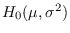 be the hypothesis that
be the hypothesis that 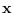 is a set of
is a set of
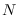 independent identically distributed
Gaussian samples with mean
independent identically distributed
Gaussian samples with mean 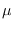 and variance
and variance 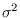 .
We now show that is a
sufficient statistic for
.
We now show that is a
sufficient statistic for
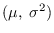 , and an ROS for is the set of all
PDFs traced out by
.
We have
, and an ROS for is the set of all
PDFs traced out by
.
We have
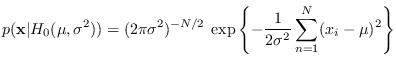 |
(2.14) |
It is well known [15] that 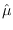 and
and
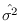 are statistically independent, so they can be treated
separately. Furthermore, under ,
are statistically independent, so they can be treated
separately. Furthermore, under ,
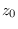 is Gaussian with mean and variance
is Gaussian with mean and variance
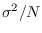 , thus
, thus
Also,
is a chi-square RV with 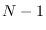 degrees of freedom
derived from a zero-mean Normal distribution with variance
degrees of freedom
derived from a zero-mean Normal distribution with variance
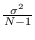 (See Section 17.1.2), thus
(See Section 17.1.2), thus
It may be verified, either by simulation, or by expanding and canceling terms,
the contributions of and are exactly canceled in the J-function ratio
See software/test_mv2.m.
Because
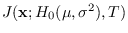 is independent of
is independent of
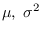 ,
it is possible to make both and a function of the data
itself, changing them (floating) with each input sample.
The most logical approach would be to set
,
it is possible to make both and a function of the data
itself, changing them (floating) with each input sample.
The most logical approach would be to set 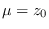 and
and
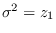 .
But, if
is independent of
, one may question why
we would bother to do it. The reason is purely numerical.
While this example is a trivial case, in general we do not
have exact formulas for the PDFs, particularly the denominator
.
Therefore, our approach is to position within the ROS of
to simultaneously maximize the numerator PDF and the denominator.
By doing this, we are allowed to use PDF approximations
such as the central limit theorem (CLT)
(see
software/test_mv2.m).
.
But, if
is independent of
, one may question why
we would bother to do it. The reason is purely numerical.
While this example is a trivial case, in general we do not
have exact formulas for the PDFs, particularly the denominator
.
Therefore, our approach is to position within the ROS of
to simultaneously maximize the numerator PDF and the denominator.
By doing this, we are allowed to use PDF approximations
such as the central limit theorem (CLT)
(see
software/test_mv2.m).
Example 4
We now expand upon the previous example by using a floating reference hypothesis
and a CLT approximation for
the denominator PDF. The feature was Gaussian, with mean
and variance
. Therefore the PDF obtained
using the CLT is the same as the true PDF. But, for 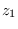 , we need to compute the
mean and variance under
. In particular,
the expected value of is and the variance is
, we need to compute the
mean and variance under
. In particular,
the expected value of is and the variance is
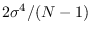 (See Section 17.1.2).
The theoretical Chi-square PDF and Gaussian PDF based on the CLT are
plotted together for
(See Section 17.1.2).
The theoretical Chi-square PDF and Gaussian PDF based on the CLT are
plotted together for 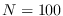 in Figure 2.3. There is close agreement near the
central peak. And while not visible
in the PDF plot (top panel), there are huge errors in the tail regions visible
on the log-PDF plot (bottom panel). Using the CLT PDF estimate in place of the Chi-square distribution,
we obtain a J-function estimate. Figure 2.4 shows the result
of comparing the J-function using a CLT PDF estimate with the exact J-function.
We used Gaussian data with variance and mean chosen at random (not corresponding to ).
We used a floating reference hypothesis (
in Figure 2.3. There is close agreement near the
central peak. And while not visible
in the PDF plot (top panel), there are huge errors in the tail regions visible
on the log-PDF plot (bottom panel). Using the CLT PDF estimate in place of the Chi-square distribution,
we obtain a J-function estimate. Figure 2.4 shows the result
of comparing the J-function using a CLT PDF estimate with the exact J-function.
We used Gaussian data with variance and mean chosen at random (not corresponding to ).
We used a floating reference hypothesis (
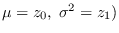 .
The error is on the order 1e-3 for log-J function values ranging from -400 to 200!
It is clear that using the floating reference hypothesis makes the approach feasible.
See software/test_chisq_clt.m.
.
The error is on the order 1e-3 for log-J function values ranging from -400 to 200!
It is clear that using the floating reference hypothesis makes the approach feasible.
See software/test_chisq_clt.m.
Figure 2.3:
Example of Gaussian CLT approximation (red dotted)
with true Chi-square PDF (blue solid).
|
|
Figure:
Example of J-function estimation using CLT approximation.
Horizontal axis is the true log-J function
and the vertical axis is the CLT approximation.
Clearly the CLT approximation is very bad when used with a fixed
but very good when used with a floating reference hypothesis.
|
|
Since we position near or at the maximum
of
, we may ask whether there is a relationship
to maximum likelihood (ML).
We will explore the relationship of this
method to asymptotic ML theory in a later section.
To indicate the dependence of on
, we adopt the notation
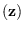 . Thus,
. Thus,
The existence of on the right side of the
conditioning operator  is admittedly
a very bad use of notation, but is done for simplicity.
is admittedly
a very bad use of notation, but is done for simplicity.
In many problems, the ROS
is not easily found
and we must be satisfied with an approximate ROS.
In this case, there is a weak dependence
of
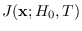 upon .
This dependence is generally unpredictable unless, as we have suggested,
is always chosen to maximize the numerator PDF.
Then, the behavior of
is somewhat
predictable. By maximizing the numerator,
the result is often a positive bias. This positive bias
is most notable when there is a good match
to the data - a desirable feature.
upon .
This dependence is generally unpredictable unless, as we have suggested,
is always chosen to maximize the numerator PDF.
Then, the behavior of
is somewhat
predictable. By maximizing the numerator,
the result is often a positive bias. This positive bias
is most notable when there is a good match
to the data - a desirable feature.
Another example of the use of the CLT is provided in section
5.2.4.
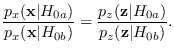
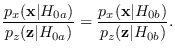
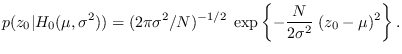
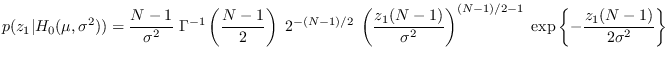
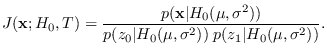
![\includegraphics[scale=0.6, clip]{test_chisq_clt.eps}](img203.png)
![\includegraphics[width=4.0in,height=3.0in, clip]{test_chisq_clt_comp.eps}](img204.png)