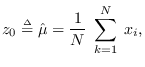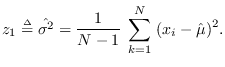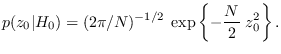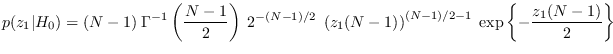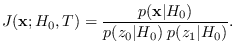The Fixed Reference Hypothesis and the PDF tail problem
Under normal sitiations, it is highly unlikely, that the
data 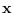 lies near the central peak of
lies near the central peak of
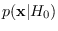 .
It is far likelier that it is in the far tails.
This will cause the numerator and denominator
PDFs in (2.3)
to approach zero. Representing the PDF value may be well below
the machine precision. But, as long as the log of
and
.
It is far likelier that it is in the far tails.
This will cause the numerator and denominator
PDFs in (2.3)
to approach zero. Representing the PDF value may be well below
the machine precision. But, as long as the log of
and
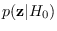 may
be represented accurately, this is not an issue, as all calculations
of this sort can (and should) be done in the log domain.
As the reader will discover through
experience, as varies over a wide range of values,
there may be large variations in the individual terms, but by and large,
the difference
may
be represented accurately, this is not an issue, as all calculations
of this sort can (and should) be done in the log domain.
As the reader will discover through
experience, as varies over a wide range of values,
there may be large variations in the individual terms, but by and large,
the difference
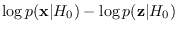 remains within fairly reasonable range of values.
remains within fairly reasonable range of values.
Example 1
We now consider the feature set pair consisting of
the sample mean and variance
![${\bf z}= [z_0, z_1]$](img136.png) ,
where
,
where
Let 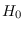 be the hypothesis that is a set of
be the hypothesis that is a set of
 independent identically distributed
Gaussian samples with mean 0 and variance 1.
We have
independent identically distributed
Gaussian samples with mean 0 and variance 1.
We have
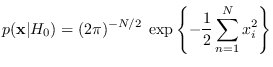 |
(2.11) |
It is well known [15] that under
Gaussian 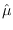 and
and
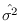 are statistically independent, so they can be treated
separately. Furthermore, under ,
are statistically independent, so they can be treated
separately. Furthermore, under ,
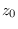 is Gaussian with mean 0 and variance
is Gaussian with mean 0 and variance 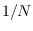 , thus
, thus
Also,
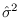 is a chi-square RV with
is a chi-square RV with 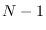 degrees of freedom
derived from a zero-mean Normal distribution with variance
degrees of freedom
derived from a zero-mean Normal distribution with variance
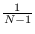 (See Section 17.1.2), thus
(See Section 17.1.2), thus
Finally, for the J-function we have
We simulated this example using 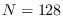 . Data was created with mean
uniformly distributed between -5 and 5, and variance uniformly
distributed from 0 to 100. In ten random trials,
and
numerically underflowed (evaluated to zero)
nine of the ten times.
When the log-PDFs were evaluated instead, the log-PDF
values ranged across a wide range from -7000 to -629.
The log-J function ranged from -448 to -310.
See software/test_mv.m.
. Data was created with mean
uniformly distributed between -5 and 5, and variance uniformly
distributed from 0 to 100. In ten random trials,
and
numerically underflowed (evaluated to zero)
nine of the ten times.
When the log-PDFs were evaluated instead, the log-PDF
values ranged across a wide range from -7000 to -629.
The log-J function ranged from -448 to -310.
See software/test_mv.m.
In the above example, an analytic expression is available
for
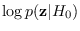 . This is not the case in general.
The types of transformations and reference hypotheses
for which analytic expressions are available are limited.
We will see in the following sections how these problems can be alleviated.
. This is not the case in general.
The types of transformations and reference hypotheses
for which analytic expressions are available are limited.
We will see in the following sections how these problems can be alleviated.