Algorithm Summary
We now briefly summarize the MR-HMM algorithm.
The MR-HMM algorithm has three potential goals: (a) calculate
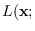
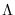
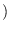 , (b) determine the most likely path and its
likelihood value, and (c) update the MR-HMM parameters
(re-estimation).
We start with a set of initial MR-HMM parameters (Initialization is covered in Section 14.2.8).
To re-estimate the discrete parameters of the proxy-HMM,
we first use the standard Baum-Welch
algorithm [65] on the proxy HMM
to obtain the expanded proxy STM and prior state probabilities,
then “compress" them to obtain
, (b) determine the most likely path and its
likelihood value, and (c) update the MR-HMM parameters
(re-estimation).
We start with a set of initial MR-HMM parameters (Initialization is covered in Section 14.2.8).
To re-estimate the discrete parameters of the proxy-HMM,
we first use the standard Baum-Welch
algorithm [65] on the proxy HMM
to obtain the expanded proxy STM and prior state probabilities,
then “compress" them to obtain 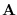 and
and
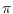 .
Compressing means squeezing the estimated proxy STM,
which is
.
Compressing means squeezing the estimated proxy STM,
which is
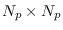 , to size
, to size
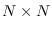 by
by summing up all the transitions from the end of
any partition to the start of another partition
according to state. The feature PDF estimates
by
by summing up all the transitions from the end of
any partition to the start of another partition
according to state. The feature PDF estimates
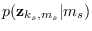 used in (14.4)
can also be re-estimated
in a straight-forward way using the gamma probabilities
[73], analogous to the standard Baum-Welch
algorithm [65]. The MR-HMM algorithm
proceeds as follows:
used in (14.4)
can also be re-estimated
in a straight-forward way using the gamma probabilities
[73], analogous to the standard Baum-Welch
algorithm [65]. The MR-HMM algorithm
proceeds as follows:
- compute the segment likelihood values (see Section 14.2.5),
- Use these to compute the proxy HMM segment likelihood
values on a base-segment basis (14.3),
- Create the proxy HMM STM and initial
probabilities from the MR-HMM parameters
in the manner described in Section 14.2.3,
- compute the forward procedure
for the proxy HMM as described for the traditional
HMM (eqs. (12-20) of [65]),
producing the forward probabilities
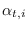 ,
,
- from
, calculate
(eq. (20) of [65]).
Or, if only classifying or segmenting data,
compute the best trellis path
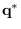 using the Viterbi
algorithm (Section III.B [65]).
In place of
,
we use the best path probability
using the Viterbi
algorithm (Section III.B [65]).
In place of
,
we use the best path probability
using (14.2) and equation (14) in [65]
to compute
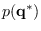 .
.
- If only
or the best trellis path
and likelihood is desired, then exit.
If MR-HMM parameter re-estimation or
a posteriori state probabilities are desired,
then
- compute the backward probabilities
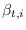 (eqs. (23-25) of [65]),
(eqs. (23-25) of [65]),
- Use
,
and the
proxy STM to compute the a posteriori state probabilities
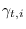 (See eq. (27) in [65]),
(See eq. (27) in [65]),
- To compute the a posteriori
probability of each sub-class (i.e. bottom of
Figure 14.1), add up
across all the partitions within the sub-class,
- Re-estimate the proxy STM and initial probabilities,
(eq. (40) in [65]),
- Determine the MR-HMM sub-class
transition matrix
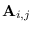 , initial probabilities
, initial probabilities
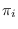 , and segment size probabilities
, and segment size probabilities
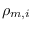 by averaging the proxy initial probabilities and STM
in the obvious way,
by averaging the proxy initial probabilities and STM
in the obvious way,
- Update the segment PDF Gaussian mixtures.
This process differs somewhat from the standard HMM because
the proxy HMM has a bloated number of states, most of which
are just wait-states. Only the proxy states to pay attention to
are the first wait state of a partition (See Figure 14.1).
A non-zero
in these positions indicates the
probability of a given sub-class, segment size, and time delay.
The segment PDFs are updated as in eq. (52)-(54) in [65],
with this sublety in mind.
Note that considerable (order of magnitude or more)
memory and computational savings can be had by
taking advantage of the highly sparse and structured
proxy HMM state transition matrix in the above steps.
This is all done by the CMEX software
software/alphabetacompress.c.