Computation of segment Likelihood functions using PPT
In (14.2), the PDFs
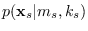 are the segment PDFs
conditioned on knowing the segment sub-class (the
segment sub-classes are assumed to be fixed for each
segmentation
are the segment PDFs
conditioned on knowing the segment sub-class (the
segment sub-classes are assumed to be fixed for each
segmentation 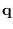 ). These are obtained using the PPT (equation 2.2)
and a feature transformation specific to sub-class
). These are obtained using the PPT (equation 2.2)
and a feature transformation specific to sub-class
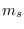 on a segment of length
on a segment of length 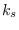 base segments:
base segments:
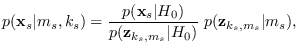 |
(14.4) |
where
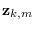 is the feature used
for a segment of size
is the feature used
for a segment of size 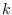 and sub-class
and sub-class 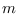 ,
,
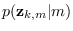 is the PDF of that feature assuming sub-class ,
and
is the PDF of that feature assuming sub-class ,
and
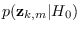 is the PDF of that feature
under the reference hypothesis.
This calculation has been described for a range of different
features (See chapters 4
through 11).
The MR-HMM requires a large amount of
front-end processing to calculate all the necessary features
and PDFs for all segments (seen in Figure 14.1 “Available segments")
assuming each possible sub-class.
is the PDF of that feature
under the reference hypothesis.
This calculation has been described for a range of different
features (See chapters 4
through 11).
The MR-HMM requires a large amount of
front-end processing to calculate all the necessary features
and PDFs for all segments (seen in Figure 14.1 “Available segments")
assuming each possible sub-class.