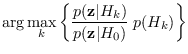Next: Chain Rule Up: Mathematical Definition of PDF Previous: Optimality Conditions of the Contents
Some authors have proposed using ad-hoc reference hypotheses with (2.8),
such as collections of data classes (“all classes" hypothesis) [11,12].
In this case,
![]() can be estimated, along with the class PDFs
can be estimated, along with the class PDFs
![]() .
These methods are techically not using PDF projection,
and definitely not maximum entropy PDF projection.
This is not to say that these methods do not have merit. On the contrary,
using the “union class" hypothesis (union of all classes)
as a reference hypothesis may have advantages
in classifying among a set of similar classes
based on total KL divergence[13] (thanks fo Steven Kay for this observation).
The method has been proven, for example in text classification [14].
For additional discussion of choosing
.
These methods are techically not using PDF projection,
and definitely not maximum entropy PDF projection.
This is not to say that these methods do not have merit. On the contrary,
using the “union class" hypothesis (union of all classes)
as a reference hypothesis may have advantages
in classifying among a set of similar classes
based on total KL divergence[13] (thanks fo Steven Kay for this observation).
The method has been proven, for example in text classification [14].
For additional discussion of choosing ![]() for maximum entropy, See Section
3.2.3.
for maximum entropy, See Section
3.2.3.