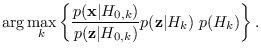Next: Class-Specific Feature Mixture (CSFM) Up: Likelihood Comparison and Combination Previous: Likelihood Comparison and Combination Contents
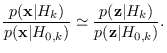
This optimality goal can be approximated individually for each class
to maximize the sufficiency or minimize the dimension of the features.
Take for example, sinewaves in colored noise.
With a white-noise reference hypothesis,
the feature set must be sufficient for
“white noise" vs. “colored noise plus sinewave",
so must include parameters describing the sinewaves
and the background spectrum. A feature set such as
the SINAR model (Section 9.2) could be used.
On the other hand, if the background spectrum is known,
this background spectrum (without sinewaves) would make a better
choice for ![]() . Then, the features
would only need to be sufficient for
“colored noise" vs. “colored noise plus sinewave",
so would only need to describe the detected sinewaves.
. Then, the features
would only need to be sufficient for
“colored noise" vs. “colored noise plus sinewave",
so would only need to describe the detected sinewaves.
Equation (2.2) also makes the one class, one feature assumption, where for each class, there is a “best" feature. This assumption may not be appropriate in some problems. In some cases, data is collected imprecicely, or collections of data may consist of mixtures of different physical phenomena. Or, interference or background noise may vary. In (12.4), the J-function (2.3) usually dominates, thus potentially causing classification errors for data that has characteristics better represented by a different feature. In these cases, it is better to use the class-specific feature mixture (CSFM).