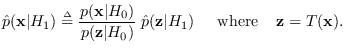Next: Class-Specific Feature Classifier Up: Generation of Samples from Previous: Generation of Samples from Contents
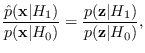 |
(2.7) |
This result gives us guidance about how to choose not just
the features, but also ![]() .
In short, in order to make the projected
PDF as good as possible an approximation to
.
In short, in order to make the projected
PDF as good as possible an approximation to
![]() , choose
, choose
![]() and
and ![]() so that
so that
![]() is approximately sufficient statistic for
the likelihood ratio test between
is approximately sufficient statistic for
the likelihood ratio test between ![]() and
and ![]() .
But, the sufficiency condition is required for optimality,
but is not necessary for 2.6 to be a valid PDF.
Here we can see the importance of the theorem
which provides a means of
creating PDF approximations on the high-dimensional
input data space without dimensionality penalty
using low-dimensional feature PDFs.
It also provides a way to optimize
the approximation by controlling both the reference hypothesis
.
But, the sufficiency condition is required for optimality,
but is not necessary for 2.6 to be a valid PDF.
Here we can see the importance of the theorem
which provides a means of
creating PDF approximations on the high-dimensional
input data space without dimensionality penalty
using low-dimensional feature PDFs.
It also provides a way to optimize
the approximation by controlling both the reference hypothesis
![]() as well as the features themselves.
This is the remarkable property of Theorem 1 - that the resulting
function remains a PDF whether or not the features are
sufficient statistics. Since sufficiency
means optimality of the classifier, approximate sufficiency
mean PDF approximation and approximate optimality.
as well as the features themselves.
This is the remarkable property of Theorem 1 - that the resulting
function remains a PDF whether or not the features are
sufficient statistics. Since sufficiency
means optimality of the classifier, approximate sufficiency
mean PDF approximation and approximate optimality.