Chain Rule
Most useful signal processing occurs in several stages.
We have up to now only considered the transformation as a whole
rather than the individual stages. Assuming that the transformation
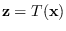 can be broken into parts, for example,
can be broken into parts, for example,
equation (2.2) takes on the chain-rule form:
![$\displaystyle G({\bf x}) =
\left[ \frac{ p({\bf x}\vert H_{0x})} {p({\bf y}\ver...
... \frac{ p({\bf w}\vert H_{0w})} {p({\bf z}\vert H_{0w})} \right] \; g({\bf z}),$](img130.png) |
(2.9) |
where
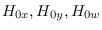 are reference hypotheses
used at each stage. The J-function of
are reference hypotheses
used at each stage. The J-function of
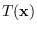 is the product of the three
stage-wise J-functions.
To understand the importance of the chain-rule,
consider how we would cope without it. We would need to
solve for
is the product of the three
stage-wise J-functions.
To understand the importance of the chain-rule,
consider how we would cope without it. We would need to
solve for
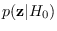 , the PDF of
, the PDF of 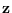 under the assumption that
under the assumption that
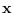 had PDF
had PDF 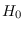 . But, at each stage, the distribution
of the output feature becomes more and more intractable.
Thus, at the end of a long signal processing
chain, we would be unable to derive
.
Estimating
is futile since the
is generally evaluated in the far tails of the distribution,
and can only realistically be represented in log form,
and by a closed-form expression.
. But, at each stage, the distribution
of the output feature becomes more and more intractable.
Thus, at the end of a long signal processing
chain, we would be unable to derive
.
Estimating
is futile since the
is generally evaluated in the far tails of the distribution,
and can only realistically be represented in log form,
and by a closed-form expression.
On the other hand, using the chain-rule, we can “re-start"
the process by assuming a suitable canonical form for
at the start of each stage.
As we mentioned, and will shortly see, for MaxEnt, this canonical will be
decided by the choice of feature transformation.
Incidentally, (2.9) can be used for the calculation of
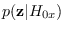 , which is otherwise intractible.
Let
be the combined transformation of the chain.
Then,
, which is otherwise intractible.
Let
be the combined transformation of the chain.
Then,
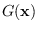 above is also equal to
above is also equal to
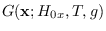 . Using (2.9) and (2.2),
we have
. Using (2.9) and (2.2),
we have
![$\displaystyle p({\bf z}\vert H_{0x})=
\frac{ p({\bf x}\vert H_{0x})} {J({\bf x}...
...({\bf w}\vert H_{0y})} {p({\bf w}\vert H_{0w})} \right]
p({\bf z}\vert H_{0w}).$](img134.png) |
(2.10) |
The implementation of (2.10) requires that we can solve for the PDF of the
feature at the output of each stage under the reference hypothesis proposed
at the input of the stage.