Next: Hanning-3 Example Experiment Up: Segmentation and Window Functions Previous: Block Segmentation Contents
To use various hanning-3 segmentations together
in a class-specific classifier, we need to apply the concept
of virtual input data.
Consider two hanning-3 segmentations with different
segment sizes ![]() and
and ![]() ,
denoted by
,
denoted by
![]() and
and
![]() .
It has been shown [57]
that with weights
.
It has been shown [57]
that with weights ![]() as defined in (12.3),
that
as defined in (12.3),
that
![]() and
and
![]() are related by an orthogonal linear transformation.
Specifically, there exists an ortho-normal matrix
are related by an orthogonal linear transformation.
Specifically, there exists an ortho-normal matrix ![]() such that
such that
![]() In Figure 12.2,
the output of each segmentation operation is considered
as the “virtual input data" of each branch.
Each branch has a different virtual input data, but they are
considered “equivalent". Therefore, the projected
likelihood function for
In Figure 12.2,
the output of each segmentation operation is considered
as the “virtual input data" of each branch.
Each branch has a different virtual input data, but they are
considered “equivalent". Therefore, the projected
likelihood function for
![]() may be compared
to the projected the likelihood function for
may be compared
to the projected the likelihood function for
![]() .
.
Each block “feature calculation" in the figure
normally consists of more than one stage, organized as a chain
(See Section 2.2.4). The starting reference hypothesis
(![]() in equation 2.9) is typically
canonical reference hypothesis, exponential or Gaussian,
in which all the elements of
in equation 2.9) is typically
canonical reference hypothesis, exponential or Gaussian,
in which all the elements of ![]() are independent.
Thus, all the elements of
are independent.
Thus, all the elements of
![]() are assumed
independent under
are assumed
independent under ![]() .
Because each data space can be converted to another using an orthonormal rotation,
the projected PDFs of all the branches can be considered
PDFs in some common data space (a virtual data space).
.
Because each data space can be converted to another using an orthonormal rotation,
the projected PDFs of all the branches can be considered
PDFs in some common data space (a virtual data space).
The mathematical postulations of Hanning-3 can be tested using the function
software/hanning3_wts.m, with syntax [w,W,A]=hanning3_wts(K,N);.
The outputs include w, which is the weight vector
![]() , W which is the
, W which is the ![]() matrix of
window functions, and A is the
matrix of
window functions, and A is the
![]() linear expansion matrix that creates
linear expansion matrix that creates
![]() from
from ![]() in one column.
In Figure 12.3, we plotted W as an image
for
in one column.
In Figure 12.3, we plotted W as an image
for ![]() ,
, ![]() for which there are
for which there are
![]() segments, and for
segments, and for ![]() ,
, ![]() for which there are
for which there are
![]() segments. In the figure, you can see the circular indexing.
segments. In the figure, you can see the circular indexing.
Let ![]() be the matrix A produced for
the given value of
be the matrix A produced for
the given value of ![]() . It is easy to verify in either case that
. It is easy to verify in either case that
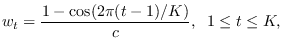
![\includegraphics[height=2.5in,width=5.5in]{hann23.eps}](img1342.png)
![\includegraphics[height=2.5in,width=2.0in]{h3192.eps}](img1355.png)
![\includegraphics[height=2.5in,width=2.0in]{h3768.eps}](img1356.png)