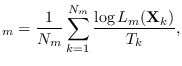We evaluated both likelihood function types (a) straight HMM on the un-augmented features,
and (b) DAF-HMM that had been corrected by
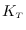 , on each data set.
For each data set and likelihood function type, we measured
mean log-likelihood and classification error rate.
Let
, on each data set.
For each data set and likelihood function type, we measured
mean log-likelihood and classification error rate.
Let
where
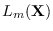 is a likelihood function for
class
is a likelihood function for
class 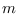 ,
, 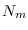 is the number of testing samples
for class , and
is the number of testing samples
for class , and 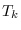 is the length of the
feature stream for sample
is the length of the
feature stream for sample 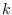 . We only evaluated a likelihood
function on data from it's own class.
We assume that the testing samples have been separated
from the training data used to train
.
To separate the data, we trained on half of the available samples,
then determined
. We only evaluated a likelihood
function on data from it's own class.
We assume that the testing samples have been separated
from the training data used to train
.
To separate the data, we trained on half of the available samples,
then determined
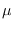
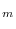 on the other half. We then switched
the halves and avaraged the results.
We also evaluated the classification error rate in percent for each
likelihood function type, using the same data separation.
on the other half. We then switched
the halves and avaraged the results.
We also evaluated the classification error rate in percent for each
likelihood function type, using the same data separation.