All PDFs were modeled as an HMM with Gaussian state PDFs
(single-component Gaussian mixture) in accordance with
the method of Rabiner [65].
We used 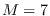 Markov states for HMM.
We used fewer Markov states (
Markov states for HMM.
We used fewer Markov states (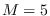 ) for DAF-HMM.
These numbers were chosen by trial and error
to provide the best classification performance.
It makes intuitive sense also.
The additional derivative information inherent in DAF permits modeling
dynamic behavior with fewer discrete states.
Also, the increased feature dimension of DAF makes it
wise to reduce the number of states, or risk over-
parameterization.
Each PDF was estimated from training data using five trials
in which the initial parameters were randomly initialized.
The PDF parameters achieving the highest log-likelihood
after convergence was chosen.
) for DAF-HMM.
These numbers were chosen by trial and error
to provide the best classification performance.
It makes intuitive sense also.
The additional derivative information inherent in DAF permits modeling
dynamic behavior with fewer discrete states.
Also, the increased feature dimension of DAF makes it
wise to reduce the number of states, or risk over-
parameterization.
Each PDF was estimated from training data using five trials
in which the initial parameters were randomly initialized.
The PDF parameters achieving the highest log-likelihood
after convergence was chosen.