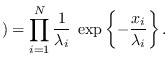Predicting the Mean (centroid) of MCMC-UMS.
For convex manifolds, the manifold centroid
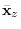 is the center of mass in Figure 5.8 and is on the manifold.
It is also the conditional mean
is the center of mass in Figure 5.8 and is on the manifold.
It is also the conditional mean
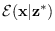 ,
and is an optimal point with respect to a deterministic entropy
measure. It has applications in feature inversion,
image reconstruction and spectral estimation.
,
and is an optimal point with respect to a deterministic entropy
measure. It has applications in feature inversion,
image reconstruction and spectral estimation.
The centroid can be approximated by the sample mean
of samples generated using UMS, or
much more efficiently using the “surrogate density"
approach, which we now explain. Let
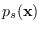 , be a PDF with support on
, be a PDF with support on 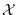 (not limited to the manifold), but sharing four properties with
(not limited to the manifold), but sharing four properties with
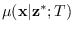 :
(a) its mean
:
(a) its mean 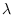 lies on the manifold, so
lies on the manifold, so
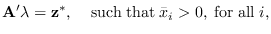 |
(5.12) |
(b) it has constant density along the manifold (meaning that
the gradient in a direction aligned with the manifold is zero),
(c) it has maximum possible entropy under the
constraint (5.12), and (d) it has support in all of ,
but itsprobability mass is concentrated
near the manifold. This idea is illustrated in Figure 5.9.
The property that the samples congregate near the manifold
for 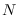 large can be justified by the law of large numbers
(See Appendix in [24]). As a result,
the surrogate density converges effectively to the manifold distribution.
Therefore, the mean
of the surrogate density
is a very good approximation to the manifold centroid
at high dimensions.
large can be justified by the law of large numbers
(See Appendix in [24]). As a result,
the surrogate density converges effectively to the manifold distribution.
Therefore, the mean
of the surrogate density
is a very good approximation to the manifold centroid
at high dimensions.
Figure:
Illustration of surrogate density. An arbitrary sample 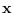 is decomposed into a component
is decomposed into a component 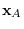 in the column space
of
in the column space
of 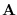 and the orthogonal component
and the orthogonal component 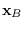 . At high dimension,
samples congregate near the manifold where
. At high dimension,
samples congregate near the manifold where
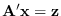 and are equally distributed along the manifold.
and are equally distributed along the manifold.
|
|
The property that the surrogate distribution is uniform
along the manifold can be seen once we select the
surrogate density and maximize its entropy.
It is known that the exponential density
has the highest entropy among all densities
for positive-valued with specified mean
[39].
We therefore propose to use (5.13)
as the surrogate density for
,
by maximizing the entropy of (5.13)
over
, subject to
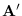
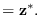 The entropy of (5.13) is
The entropy of (5.13) is
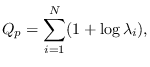 |
(5.14) |
where “p" indicates positive data case.
If we use (5.10) to write
in terms of 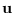 ,
we can maximize
,
we can maximize 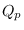 over . The solution must meet the requirement
that the derivatives of the entropy with respect to
over . The solution must meet the requirement
that the derivatives of the entropy with respect to 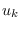 are zero, or
are zero, or
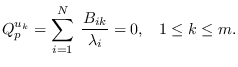 |
(5.15) |
This condition forces the distribution to be constant on the manifold.
To see this, first, let be decomposed as (See Figure 5.9),
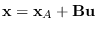 , where matrix
, where matrix 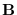 spans the subspace orthogonal
to matrix . Note that changes to vector
will move within the manifold, but not change
its projection onto the columns of ,
so remains on the manifold.
Therefore, a distribution is constant on the manifold
if and only if its derivative w/r to is zero.
It is easily shown that the derivative of
spans the subspace orthogonal
to matrix . Note that changes to vector
will move within the manifold, but not change
its projection onto the columns of ,
so remains on the manifold.
Therefore, a distribution is constant on the manifold
if and only if its derivative w/r to is zero.
It is easily shown that the derivative of
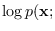
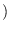 with respect to equals
with respect to equals
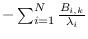 ,
making (5.15) equivalent to requiring
,
making (5.15) equivalent to requiring
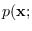 to be constant on the manifold.
to be constant on the manifold.
Incidentally, note that maximizing (5.14)
also maximizes the classical maximum entropy measure
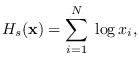 |
(5.16) |
which is used in classical
spectral estimation [40,41] and
image reconstruction [42,43].
There are two ways to solve (5.15), one requiring
a valid starting point in the manifold, and one not
requiring a starting point.
Subsections
![\includegraphics[height=2.5in,width=2.7in]{surr.eps}](img647.png)