PDF Projection validation: the Acid test
In constructing a classifier,
it is of utmost importance that the J-function is
accurate. This will insure that the
resulting projected PDF is, in fact, a valid PDF.
If the J-function is inaccurate, classification errors may occur.
To verify the “J" function, we have developed an end-to-end test that we call
the “Acid Test" because of its foolproof nature.
To use the method, it is first necessary
to define a fixed synthetic data hypothesis, denoted by 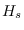 ,
for which we can compute the PDF
,
for which we can compute the PDF
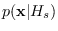 readily, and
for which we can create synthetic raw data.
Note that is not a reference hypothesis.
The synthetic data is converted into features
and the PDF
readily, and
for which we can create synthetic raw data.
Note that is not a reference hypothesis.
The synthetic data is converted into features
and the PDF
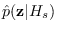 is estimated from the
synthetic features (using a Gaussian Mixture
PDF, HMM, or any appropriate parametric or non-parametric statistical model).
Next, the theoretical PDF
is compared with the
projected PDF
is estimated from the
synthetic features (using a Gaussian Mixture
PDF, HMM, or any appropriate parametric or non-parametric statistical model).
Next, the theoretical PDF
is compared with the
projected PDF
for each sample of synthetic data. The log-PDF values
are plotted on each axis and the results should fall
on the X=Y line. Since the acid test
checks the equality of two entirely different
paths, it should find any systematic error in PDF estimation
or in the J-function calculation.
To see an example of the Acid test, jump to
Section 5.2.1, example 8.