The unsegmented case is the simplest classifier form
where the complete input data 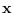 is presented directly to the feature transformation,
the feature
is presented directly to the feature transformation,
the feature 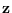 is extracted, and presented
as a single vector to the joint-PDF estimation,
typically a kernel-based approach such as
Gaussian mixtures (Section 13.2).
Applications include problems where the data
consists of a fixed-size measurement,
such as in text categorization based on
a specified set of word-counts.
is extracted, and presented
as a single vector to the joint-PDF estimation,
typically a kernel-based approach such as
Gaussian mixtures (Section 13.2).
Applications include problems where the data
consists of a fixed-size measurement,
such as in text categorization based on
a specified set of word-counts.