In what follows, the symbol 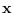 is always used for
the (high-dimensional) input data,
and the symbol
is always used for
the (high-dimensional) input data,
and the symbol 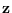 is always used for
(lower-dimensional) features, the output of
is always used for
(lower-dimensional) features, the output of
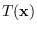 .
We view both and as random variables (RV)
2.1.
We will use a simplified notation
for a RV and the associated
probability density function (PDF).
We use the same symbol to represent the RV and a sample of that
RV. Distributions are identified by their
argument, so
.
We view both and as random variables (RV)
2.1.
We will use a simplified notation
for a RV and the associated
probability density function (PDF).
We use the same symbol to represent the RV and a sample of that
RV. Distributions are identified by their
argument, so
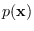 and
and
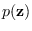 are understood
to be the distributions of RVs and , respectively.
When there is the possibility of confusion,
we use a subscript, for example,
are understood
to be the distributions of RVs and , respectively.
When there is the possibility of confusion,
we use a subscript, for example,
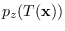 is understood
to be the evaluation of the density
at sample
is understood
to be the evaluation of the density
at sample
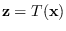 .
If there are more than one possible distributions
of a given RV, we index them by the statistical hypothesis,
such as
.
If there are more than one possible distributions
of a given RV, we index them by the statistical hypothesis,
such as
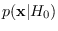 ,
,
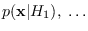 , etc.
For a generic fixed feature PDF, we use
, etc.
For a generic fixed feature PDF, we use
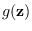 .
.