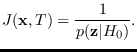The feature transformation is the same as (5.1) in Section 5.1:
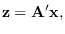 |
(7.1) |
but the similarity ends here. Because 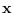 is limited to a compact set,
the unit hypercube
is limited to a compact set,
the unit hypercube
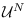 , an energy statistic is
theoretically not needed for MEPP (See Theorem 2 in Section 3.2.1)
7.1Whereas the exponential distribution played a central
role in the analysis of the singly-bounded case,
the mutivariate truncated exponential distributon (TED) plays an
important role in the unit hypercube
(all elements of in
, an energy statistic is
theoretically not needed for MEPP (See Theorem 2 in Section 3.2.1)
7.1Whereas the exponential distribution played a central
role in the analysis of the singly-bounded case,
the mutivariate truncated exponential distributon (TED) plays an
important role in the unit hypercube
(all elements of in ![$[0,1]$](img9.png) ).
The uniform reference distribution,
).
The uniform reference distribution,
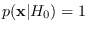 results in maximum entropy
(See Theorem 2 in Section 3.2.1), and is a special case
of the mutivariate TED. When
, the J-function
simplifies to
results in maximum entropy
(See Theorem 2 in Section 3.2.1), and is a special case
of the mutivariate TED. When
, the J-function
simplifies to
So, computing the J-function is primarily a task of computing
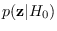 ,
which can be done using two methods as described in Section 17.7. The J-function is implemented by software/module_A_dbound.m, and
tested by software/module_A_dbound_test.m.
The re-synthesis approach using UMS is described in Secion 7.2
and implemented by software/module_A_dbound_synth.m.
,
which can be done using two methods as described in Section 17.7. The J-function is implemented by software/module_A_dbound.m, and
tested by software/module_A_dbound_test.m.
The re-synthesis approach using UMS is described in Secion 7.2
and implemented by software/module_A_dbound_synth.m.