The hidden Markov model (HMM), although having many benefits
for modeling human speech, models the data using discrete states.
It can only model continuous feature variations
using a large number of states. This problem is generally solved
by augmenting the features with time-derivatives [77].
Despite new probabilistic models that
address the dynamic behavior of features
such as segmental HMMs
[78], and a wider class of
graphical models [76],
the derivative augmented feature (DAF)
combined with hidden Markov model (DAF-HMM) remains the most widely-used
method of modeling the dynamic behavior of features.
Unfortunately, the DAF feature vector is of higher dimension with
built-in redundancy. As a result, the
assumption of conditional independence of the
observations is violated. The probability density
function (PDF), or likelihood function (LF)
of DAF cannot be compared to the PDF
of the original (un-augmented) features.
Being able to do this could enable new quantitative means of evaluating
dynamic models based on augmentation and comparing with those not based on augmentation and allow classifiers with “mixed" models, taking advantage
of DAF when necessary and using un-augmented features when not.
To this end, we derive an analytic expression for the integral of DAF-HMM model
with respect to the un-differenced input data, allowing
it to be normalized so that it integrates to one.
The computational complexity of our method is order 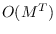 where
where
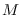 is the number of Markov states and
is the number of Markov states and 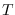 is the length of the feature
stream. But, the correction term reaches a steady-state at low values of ,
allowing an efficient means to compensate PDFs for large .
is the length of the feature
stream. But, the correction term reaches a steady-state at low values of ,
allowing an efficient means to compensate PDFs for large .