CMEX function
The main processing engine of the MR-HMM is the CMEX function alphbetacompress.c.
It can be operated in stand-alone manner separate from the Class-Specific Toolkit.
The calling syntax is:
function [alphas,alognorm,betas,blognorm,gammaN,gamma] =
alphabetacompress(Lin,S,hparm);
Definition of inputs:
- Lin: the input log-likelihoods (partial PDF values).
Each value in Lin is the assumed log-likelihood
for a segment of data for a given signal class, a given
segment length, at a specified starting base segment.
The log-likelihood value must be scaled by
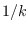 where
where
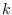 is the number of base segments in the data segment.
Matrix Lin is dimensioned nseg by Npdf, where nseg
is the total number of base segments in the input timeseries, and
Npdf is the number of PDFs (there is one PDF for each
combination of signal class and segment length).
Each PDF is evaluated at various time shifts.
It does not need to be evaluated at all time shifts
if not necessary. These positions in the matrix that are not evaluated must be
then set to negative infinity.
Since Lin contains the log-PDF of the segment
starting at the specified time, there
are many “impossible" values, which are set to negative infinity,
for example for a long segment starting near the end of the time-series.
An example of Lin is provided in Figure 14.4
which illustrates the case when there are 16 base segments
and there are two possible segment sizes: 8 and 14 base segments.
It shows where the segment log-likelihood values (scaled by ) are placed in matrix Lin.
On the left is shown a time grid with 16 base segments.
The letters indicate all the possible segments that can
exist with lengths 8 and 14 base segments.
is the number of base segments in the data segment.
Matrix Lin is dimensioned nseg by Npdf, where nseg
is the total number of base segments in the input timeseries, and
Npdf is the number of PDFs (there is one PDF for each
combination of signal class and segment length).
Each PDF is evaluated at various time shifts.
It does not need to be evaluated at all time shifts
if not necessary. These positions in the matrix that are not evaluated must be
then set to negative infinity.
Since Lin contains the log-PDF of the segment
starting at the specified time, there
are many “impossible" values, which are set to negative infinity,
for example for a long segment starting near the end of the time-series.
An example of Lin is provided in Figure 14.4
which illustrates the case when there are 16 base segments
and there are two possible segment sizes: 8 and 14 base segments.
It shows where the segment log-likelihood values (scaled by ) are placed in matrix Lin.
On the left is shown a time grid with 16 base segments.
The letters indicate all the possible segments that can
exist with lengths 8 and 14 base segments.
The column location of the likelihood value in Lin
indicates the index of the PDF.
You can put the columns in any order as long as
input variable S is correctly set (see next item).
The row location of the likelihood value in Lin indicates the
time shift. The rule is that the first position (first row)
of Lin corresponds to zero shift - such that the processing window
starts with the first base segment.
Shift values for which the processing window extends beyond nseg
are invalid. Unavailable or invalid values are indicated by -inf value.
If the input time-series is smaller than the processing window length, then
there will be no valid likelihood values in that column.
IMPORTANT: The likelihood values in Lin are normalized (divided) by the number of base
segments in the processing window (i.e. they are partial PDF values).
- S: this is a matrix of indexes that tells alphabetacompress in which column of Lin to look for
given combination of state and partition. Thus, S(istate,ipartition)=index
where index is the column number (starting with 1, not with 0).
The column width of S is the maximum number of partitions across all
states. Since some states may have more partititons, some of the values of the matrix
S are invalid and should be set to 0.
- hparm: this is the MR-HMM parameter structure with the following fields:
- N. The number of states.
- Pi. The vector of N initial state probabilities.
- A. The state transition matrix. A(i,j) is the
probabity of transitioning from state i to state j.
- state_to_class_index. This is the length-N vector of signal class indexes. This
indicates the signal class corresponding to each state. Often,
each state corresponds to a class, so state_to_class_index = [1:N];.
- pdf_to_class_index. This vector is of length Npdf
and indicates the index of the class to which each PDF belongs.
- pdf_entry. This is the vector of entry flags of length Npdf
equal to 1 or 0. A one means the given partition can be accessed from another state (i.e.
the system can start in the given signal class with that segment length).
When in doubt, set all to 1.
- ksegment: This vector is of length Npdf and
indicates the number of base segments for the corresponding pdf.
- beta_end: dimension nstate by 1, normally all ones. If
any elelemt is zero, prevents MR-HMM from ending in that state.
- PartitionDistrib. A matrix of dimension maxnpartition by
N where maxnpartition is the largest number of partitions assigned to
any class, and N is the number of states.
PartitionDistrib specifies the probability that a given partition will be chosen
conditioned on the specified state being chosen (see variable
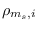 above).
above).
Figure 14.4:
Illustration of Likelihood Input matrix Lin for
a simple example with just two partitions. Time divisions
are one base segment. Entries with
“*" are set to negative infinity.
The example is trivial because there is only one valid partition of the data
: using segments A and I.
|
|
Definition of outputs:
- alphas: a nseg by Ntot matrix of expanded forward probabilities
where Ntot is the total number of wait states.
The columns of alphas are arranged in wait state counting order,
which is the order counted out if we loop over states,
then loop over the number of partitions in the signal class corresponding to the state,
then loop over the wait states in the partition.
For example, the elements of alphas for time step t are set to zero in
wait state counting order in the following loop:
icount = 1;
for i=1:N,
for j=1:P(i),
for iwait = 1:K(i,j),
alphas(t,icount)=0;
icount = icount+1;
end;
end;
end;
where P(i) is the number of partititons in the signal class assigned to state i,
and K(i,j) is the segment length in base segments for the partition.
- alognorm: a nseg by 1 vector of log-normalization values for
the forward probabilities. It is the accumulated log-correction factors
after completion of the forward procedure. The likelihood value output for the forward
procedure is computed by:
log_p_pout = log(sum(alphas(end,:)))+alognorm(end);
- betas: a nseg by Ntot matrix of expanded backward probabilities
in wait state counting order.
- blognorm: a nseg by 1 vector of log-normalization values for
the backward probabilities.
- gammaN: a nseg by N matrix. gammaN(t,i) is the posteriori
probability that the system is in state i at time step t.
- gamma: a nseg by Ntot matrix of expanded posteriori
probabilities. gamma(t,i) is the posteriori
probability that the system is in wait state i at time step t.
It is the normalized product of alphas and betas.
Columns are in wait state counting order.
![\includegraphics[width=6.0in]{mrhmm_fig.eps}](img1734.png)