Next: PDF Estimation using Gaussian Up: Feature PDF Estimation Previous: Feature PDF Estimation Contents
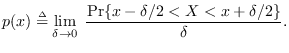
The simplest way to estimate the probability density of data is by histogram. A histogram is obtained by dividing the space of the RV into “bins", then counting the number of occurrences of the training data in each bin. A second step of smoothing or curve-fitting can be used to avoid the effects of random error. A method of PDF estimation that has become popular is that of Gaussian mixtures (GM). This can be regarded as the process of curve-fitting to a histogram where the curve is constrained to be a sum of positive Gaussian-shaped functions (modes or kernels), each with a different mean and variance. It also has the statistical interpretation of a mixture density - where each sample of the RV is regarded as having been a member of a sub-class corresponding to each mode. We will devote Section 13.2 to GM PDF estimation.
Multidimensional data,
![]() , can be modeled by a multidimensional GM. However, when data
consists of
, can be modeled by a multidimensional GM. However, when data
consists of ![]() samples of dimension
samples of dimension ![]() , it is not necessary or even desirable to
group all the data together into a single
, it is not necessary or even desirable to
group all the data together into a single ![]() -dimensional sample. In the simplest case,
all
-dimensional sample. In the simplest case,
all ![]() samples are independent and we may regard them
as samples of the same RV. Normally, however, they are not
independent. The Markovian principle assumes consecutive samples are statistically
independent when conditioned on knowing the samples that preceded it. This leads
to an elegant solution, the hidden Markov model (HMM), which employs a set of
samples are independent and we may regard them
as samples of the same RV. Normally, however, they are not
independent. The Markovian principle assumes consecutive samples are statistically
independent when conditioned on knowing the samples that preceded it. This leads
to an elegant solution, the hidden Markov model (HMM), which employs a set of
![]() PDFs of dimension
PDFs of dimension ![]() . The HMM regards each of the
. The HMM regards each of the ![]() samples
as having originated from one of
samples
as having originated from one of ![]() possible states and there is a distinct probability
that the underlying model “jumps" from one state to another. We discuss the HMM, which uses GM to
model each state PDFs, in section 13.3.
possible states and there is a distinct probability
that the underlying model “jumps" from one state to another. We discuss the HMM, which uses GM to
model each state PDFs, in section 13.3.
We discuss additional PDF models in the last section.