Let
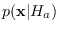 stand for a theoretical PDF from which we
can generate an unlimited amount of data.
When another theoretical class
stand for a theoretical PDF from which we
can generate an unlimited amount of data.
When another theoretical class
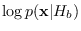 is introduced,
we can determine the classification performance of the
optimal Neyman-Pearson classifier:
is introduced,
we can determine the classification performance of the
optimal Neyman-Pearson classifier:
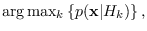 which can be compared with the performance of the classifier
that uses the projected PDFs in place of
which can be compared with the performance of the classifier
that uses the projected PDFs in place of
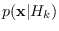 .
.